



A major bottleneck in underwater robotics is the human burden in data collection. Most pipelines are teleoperation-centric, and collecting diverse demonstrations in water is expensive and time-consuming.
UMI-Underwater tackles two practical bottlenecks in underwater manipulation: data collection cost and cross-domain generalization.
The key idea? Pair autonomous, self-supervised underwater data collection with a depth-based affordance representation that transfers directly from land to water.
A major bottleneck in underwater robotics is the human burden in data collection. Most pipelines are teleoperation-centric, and collecting diverse demonstrations in water is expensive and time-consuming.
UMI-Underwater introduces an autonomous self-supervised collector that bootstraps grasp attempts, executes recovery behaviors, and filters episodes using automatic success signals. This turns data collection into repeated deployment instead of repeated teleoperation.
If underwater data is autonomous and noisy, where do strong manipulation priors come from? Can we import them from abundant on-land human demonstrations?
RGB appearance changes dramatically underwater due to attenuation, scattering, and rapidly changing illumination. Instead of relying on RGB-only prediction, UMI-Underwater uses a depth-based affordance representation that is more stable under these shifts.
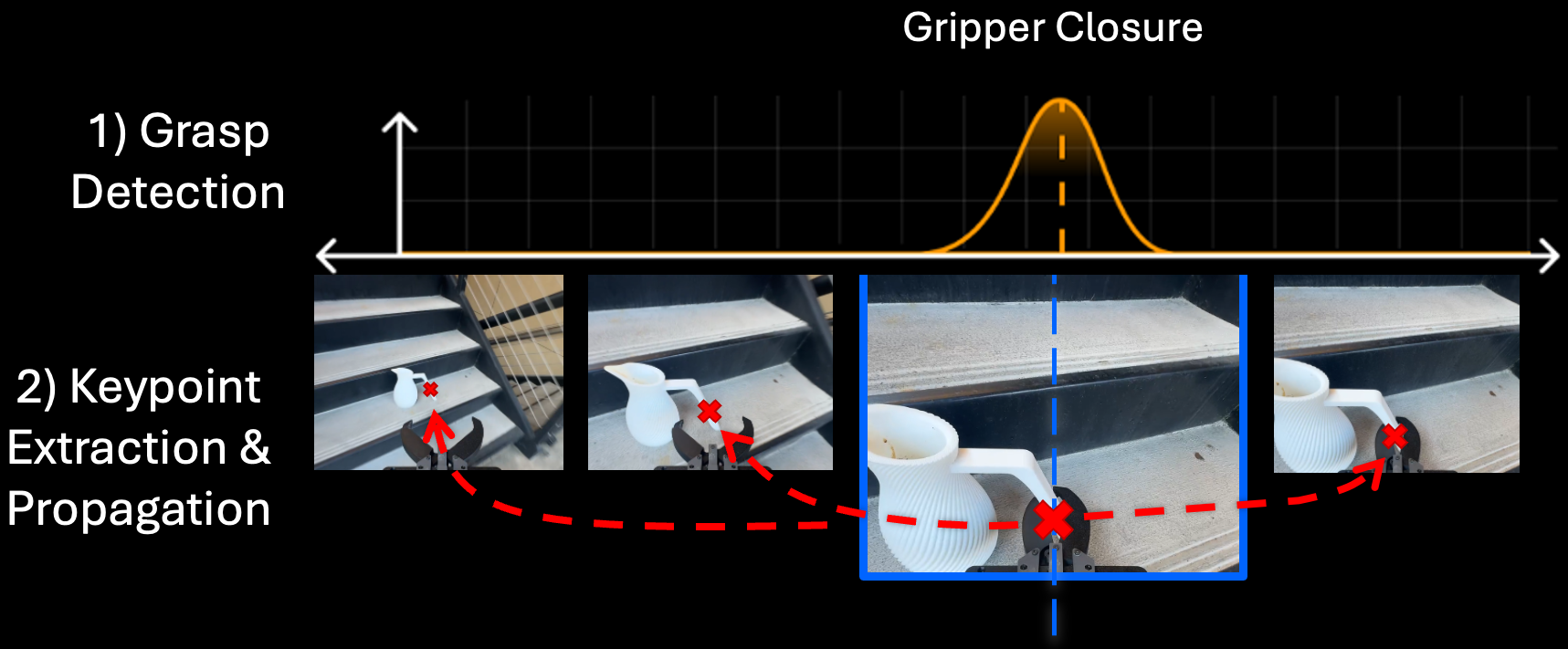
An affordance model trained on on-land handheld demonstrations is deployed underwater zero-shot via geometric alignment, providing task-level guidance before underwater policy training.
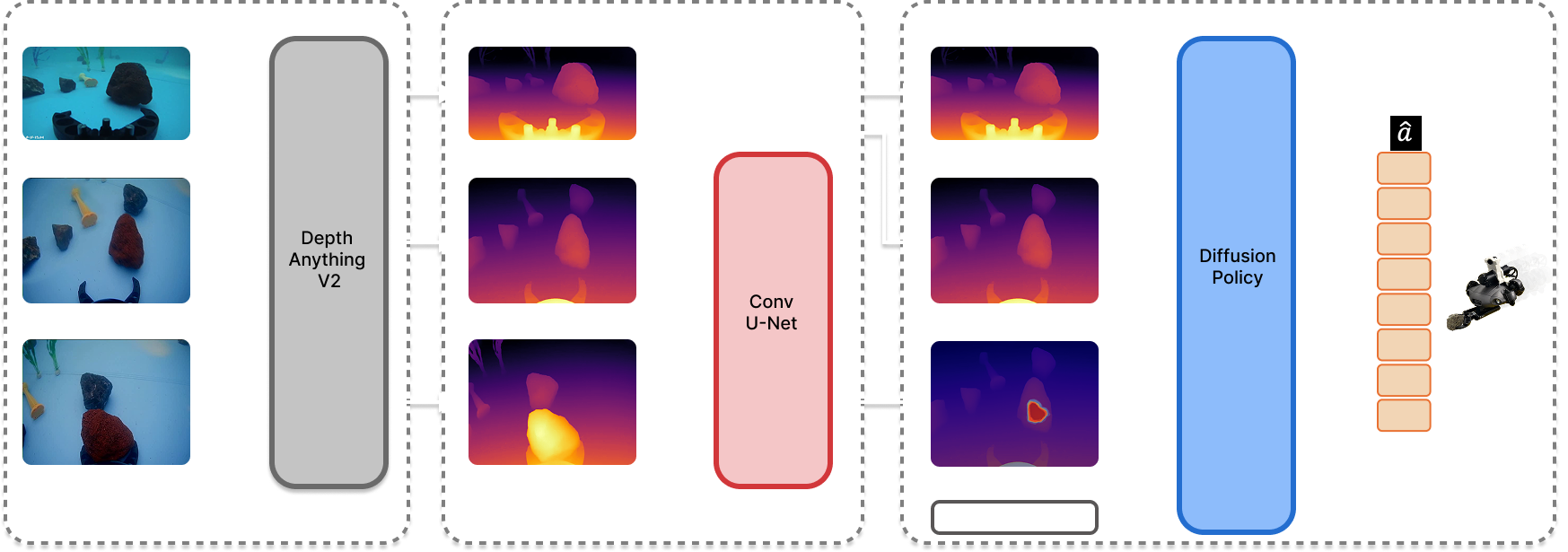
The method combines a representation layer (depth-based affordance transfer) with a control layer (affordance-conditioned diffusion policy trained on autonomous underwater data).
Representation Robustness
Depth-centric affordance transfer gives a stable geometric signal when underwater color and illumination
shift, so initialization remains reliable before large-scale underwater policy training.
Policy Robustness
Affordance-conditioned diffusion policies trained on autonomous underwater data sustain stronger grasp
performance under background shift and transfer to objects that only appear in on-land demonstrations.
UMI-Underwater uses a robot-centric loop that repeatedly attempts grasps, verifies outcomes, and retries when needed. This closed-loop structure increases data efficiency and keeps demonstration quality high without manual intervention.
@article{li2026umiunderwater,
title = {UMI-Underwater: Learning Underwater Manipulation without Underwater Teleoperation},
author = {Li, Hao and Chung, Long Yin and Goler, Jack and Zhang, Ryan and Xie, Xiaochi and Ha, Huy and Song, Shuran and Cutkosky, Mark},
journal = {Preprint},
year = {2026}
}If you have any questions, feel free to contact Hao and Clive.
Underwater RGB appearance is highly unstable because of attenuation, scattering, and changing illumination. A depth-based affordance representation is more transferable across land and water, especially for geometric grasp reasoning.
The system collects successful underwater grasp demonstrations autonomously with self-supervision, recovery behaviors, and automatic success filtering. This changes data collection from manual operation to repeatable autonomous deployment.
The affordance predictor is trained on on-land human demonstrations and deployed underwater directly, without underwater re-labeling of affordance targets, by using geometric alignment between domains.
In pool experiments, the method improves grasp success and background-shift robustness, and it generalizes to objects that were only seen in on-land data, outperforming RGB-only baselines.
Performance still depends on reliable depth cues and robust low-level execution in challenging underwater dynamics. Extending to broader tasks and harder environments remains an important next step.







